
you can also read this article in Medium -> click here
Fast prototyping and playing around with AI and ML technologies are now possible in Java, too! 🧠 🤖
Let’s create a Quarkus application that sets up a REST endpoint and calls a locally hosted Ollama model through LangChain4j. This will allow us to send questions by calling the endpoint and get responses from the Ollama model.
All of this will run on our local computer: no API keys or subscriptions needed — just pure experimenting with AI integration in a modern tech stack. In just a few easy steps, we can have all of this running:
- Install Ollama on your computer
- Create a simple Quarkus project and add the LangChain4j extension
- Create a REST Endpoint
- Call the Ollama model from the application and return the result
1. Install Ollama
Just go to their website: https://ollama.com/download.
Download the appropriate file for your OS and install it like you would install any other application. This installs the ollama command line tool, and you will be able to run ollama models locally with just a simple command like:
ollama run llama3.2:1bwhich will run the smallest available ollama model right now (~1.3 GB). It’s not a very good model, but it’s small and will run very fast locally — perfect for our use case. You can later experiment with all the free models Ollama provides — see here.
So after you run the previous command in your terminal, you should see something like this, which downloads the model, runs it, and opens a prompt where you can chat with the LLM.

But this also exposes an HTTP API on localhost, which we can interact with. That’s what we will do next with the help of Quarkus and the langchain4j extension.
2. Create a simple Quarkus project
Go to code.quarkus dev and configure the following application:
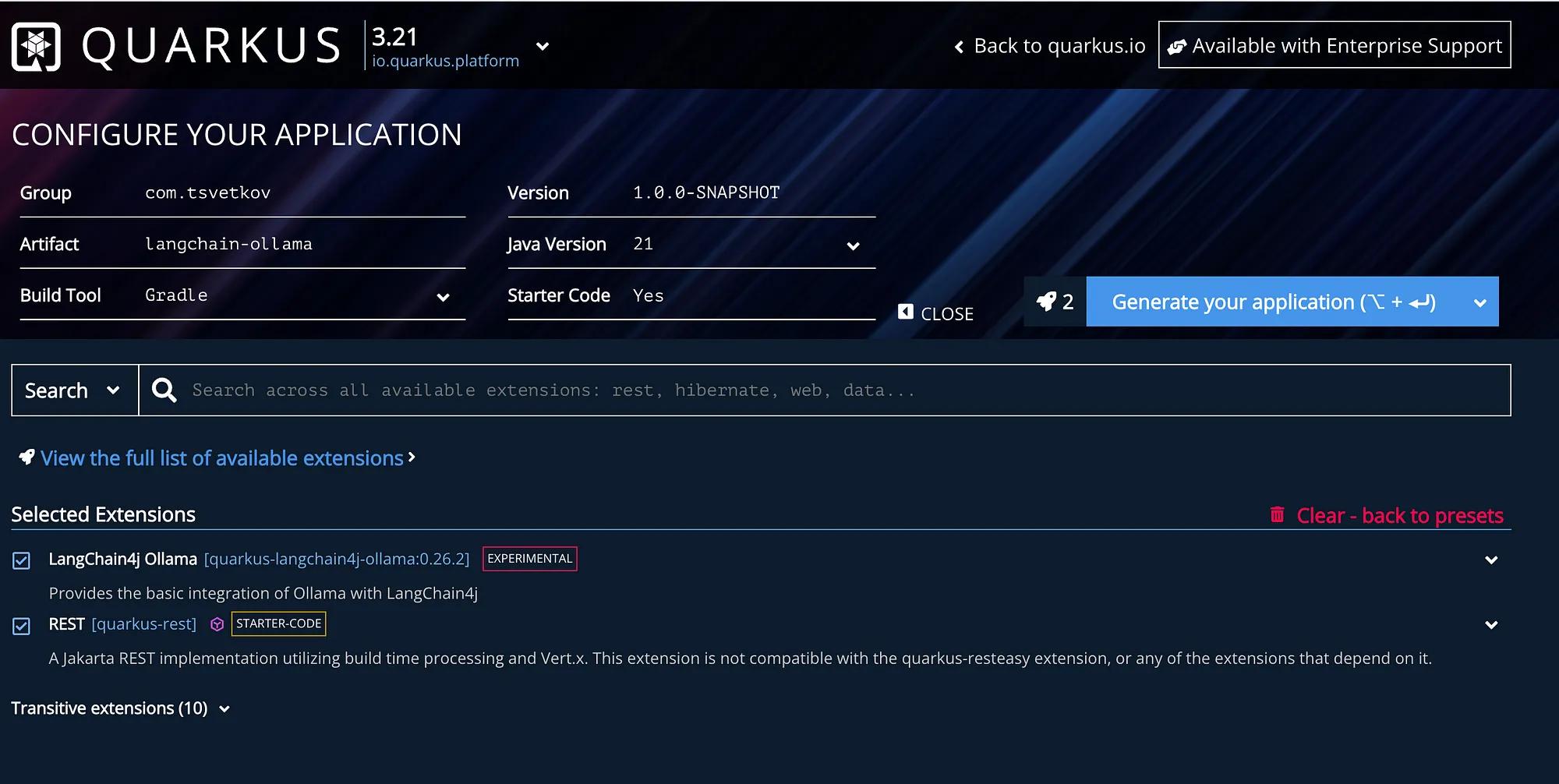
Just name the project as you wish, add the two extensions from above, and download it. Then you can open it in your favourite IDE (I use IntelliJ in all my examples).
Now, create a new Java class called OllamaService under src/main/java and add the following:
package com.tsvetkov;
import dev.langchain4j.service.UserMessage;
import io.quarkiverse.langchain4j.RegisterAiService;
import jakarta.enterprise.context.ApplicationScoped;
@RegisterAiService
@ApplicationScoped
public interface OllamaService {
public String answer( @UserMessage String question );
}We also need to explicitly set the model we downloaded in the previous step in our application.properties :
quarkus.langchain4j.ollama.chat-model.model-id=llama3.2:1b3. Create a REST Endpoint
Now, let’s create a REST Endpoint, call our service with a question, and get the result. Create a new file under src/main/java :
package com.tsvetkov;
import jakarta.inject.Inject;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
@Path("/ollama")
public class OllamaController {
@Inject
OllamaService ollamaService;
@GET
@Produces(MediaType.TEXT_PLAIN)
public String question() {
return ollamaService.answer("How are you?");
}
}You can now go to your terminal and start the application:
./gradlew quarkusDevHere’s the output you should see:

4. Call the Ollama model from the application and return the result
We can now call our /ollama endpoint and get the result. I’m using Postman for this:
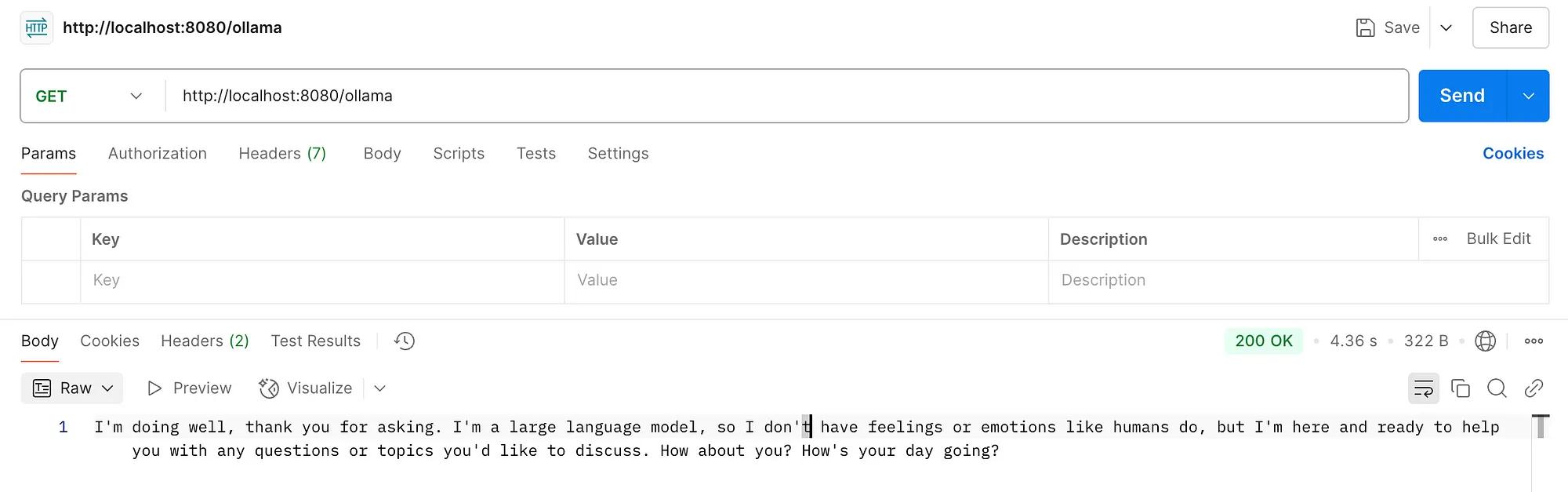
That’s it! We got the answer from our model!
We can even go one small step further and use Prompt Templates. These can be used to guide a model’s response. You can get creative here! Let’s, for example, tell the model to behave like a pirate.
Modify your OllamaService like this:
package com.tsvetkov;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.UserMessage;
import io.quarkiverse.langchain4j.RegisterAiService;
import jakarta.enterprise.context.ApplicationScoped;
@RegisterAiService
@ApplicationScoped
public interface OllamaService {
@SystemMessage("""
Act like a pirate. Speak with pirate lingo, be bold, and add a sense of adventure in your responses.
"""
)
String answer( @UserMessage String question );
}Here is the answer we get when we hit our /ollama endpoint now:
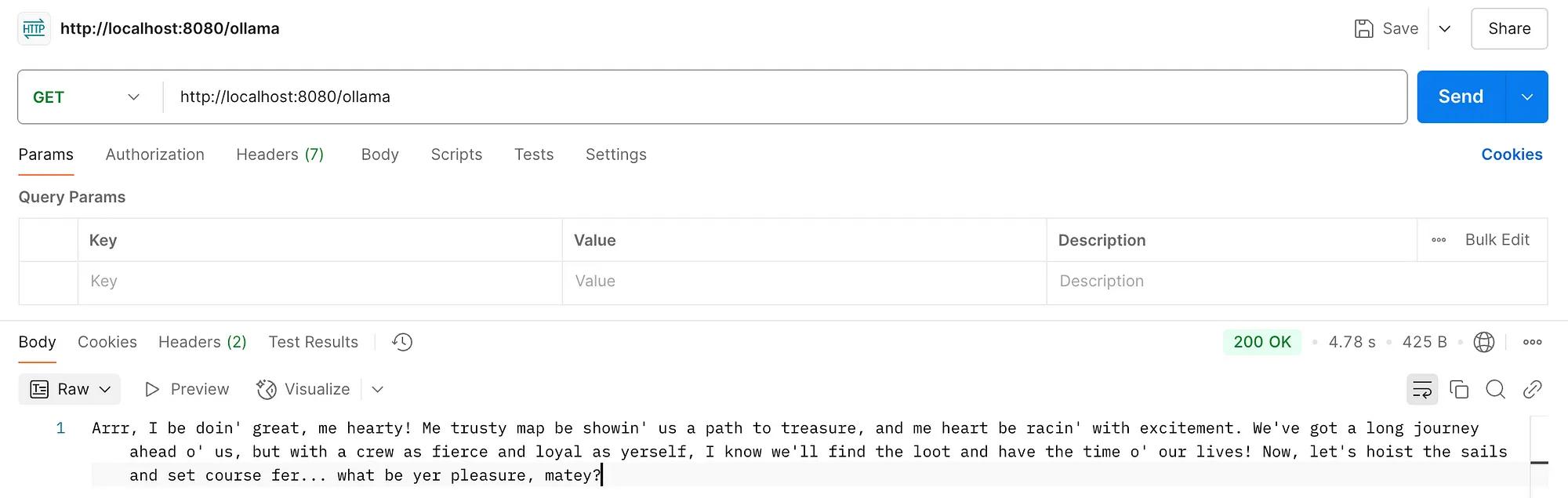
Final Thoughts
Integrating Ollama in Quarkus with LangChain4j is a very straightforward process. We’re also running the model locally, which means we have complete control over our data.
I think Java has really evolved a lot over the past few years, not only with its latest releases, but also through frameworks like Quarkus, which make working with such a tech stack very pleasant. Fast prototyping and playing around with AI and ML technologies is now a very nice experience with Java, too. This can really pave the way for new developers to experiment with such technologies and shows how these can be used in real-world enterprise applications.
Thanks for reading!